如果对于Combine具有基本的认识并书写过Combine的代码,那么对于下面这样的代码一定不陌生
1 | somePublisher.sink(receiveCompletion: { _ in |
对Combine有一定了解的人,一定不止一次的被书籍、博客或者苹果官方文档提醒,订阅某个发布者之后会返回一个AnyCancellable对象,一定要谨慎处理该AnyCancelable对象,如果不对其加以持有,那么订阅关系会在超出当前代码的作用域之后就消失掉,如果一直持有却又不释放,则会引起内存泄漏。我们在编写Combine代码的过程中,谨记书籍中、博客中以及文档中给我们的建议,在类中使用AnyCancellable的属性或者存储AnyCancellable类型的集合来存储订阅之后产生的AnyCancellable对象。正如建议所说的那样,AnyCancellable会在执行自己的deinit时释放自己的资源,按照这些建议去编写Combine代码,一切都如想象中的那样工作良好。
但是我们不应该止步于此。在我们一次又一次按照建议写出工作良好的Combine代码时一定会有所好奇:我们管理并清除的到底是什么资源?本篇文章由浅入深,举一反三,使用源码一步一步将你带进Combine的奇妙世界,让你了解Combine中的内存管理。
首先我们从事情的源头开始,最开始我们接触到的就是订阅一个Publisher之后返回的AnyCancellable对象,我们首先来看一下AnyCancellable这个类的源码
1 | public final class AnyCancellable: Cancellable, Hashable { |
- AnyCancellable可以用过两种方式来初始化,第一种传入遵循Cancellable协议的对象,会保存该对象的cancel方法,第二种通过闭包提供一个cancel方法,并保存起来
- 通过实例变量_cancel来保存初始化获得到的cancel方法
- 调用AnyCancellable类的cancel方法,自动调用内部保存的_cancel方法并清空资源持有
- 在deinit时,AnyCancellable会自动调用_cancel方法
看过了AnyCancellable我们再去探究AnyCancellable的产生过程。在最开始的代码示例中我们使用了sink,这里我们也就依然使用sink来作为一个例子,虽然Combine中的订阅者除了sink还有assign,但是其内部的逻辑都是一致的,从文章一开头以知道结尾我们一直都是使用的这种举一反三的方法去探究源码。
1 | extension Publisher { |
- 使用方法传入的参数实例化一个新的Subscriber,这个Subscriber是由Combine内部实现的Sink提供
- 调用Publisher的subscribe方法,并传入刚刚实例化的那个订阅者,建立两者之间的订阅关系
- 将刚刚创建的Subscriber包装为一个AnyCancellable方法返回
现在焦点从最初的AnyCancellable移动到了具体的Subscriber,我们就继续深入Sink这个Subscriber内部去一探究竟
1 | public final class Sink<Input, Failure: Error>: Subscriber,Cancellable { |
- SinkSubscriber内部定义了一个status字段,用来表示当前订阅者所处的状态
- 这些代码都是Subscriber协议中规定的,与发布者产生交互的方法,对这里不太明白的可以参考之前的博客:Combine核心概念
- 在SinkSubscriber的cancel方法中,会检验状态,如果状态为未关闭,则调用subscription的close方法
我们追踪了一路的各种类型的close方法,最后落在了Subscription之上,Subscription并不是具体的一个类,而是有协议抽象出来的一个角色。由于大部分Publisher都需要Subscription与自己合作来完成特定的发布行为,所以大部分Publisher都拥有Subscription内部实现类,但其实这些不同的Subscription类中不一样的主要是与各自归属的Publisher拥有不同的交互行为,如果我们但看对于内存管理方面的逻辑的话,还是大同小异的。所以依旧举一反三,这里我们就拿Future来做实例,在探究内存管理的同时还能顺便探究一下在项目中很有用的Future的内部逻辑。
Future内部提供的Subscription的实现类是Conduit
1 | // 1 |
- 这是Future内部定义的实现了Subscription协议的内部类Conduit
- 该Subscription内部会存储上游的发布者对象,以及下游的订阅者对象
- 接收到completion事件之后,主动做清理工作
- 新的订阅者订阅并开始向subscription请求数据时,会先主动询问Future内部的异步任务是否已经完成,如果完成就直接发送结果
- cancel方法中,释放自己对上游发布者对象的持有
Future,忽略锁相关
1 |
|
- Future中存储了自身的所有订阅Subscription
- Future初始化方法中接收到用户传递进来的闭包attemptToFulfill之后,立即执行该闭包。并且在attemptToFulfill闭包中通过Result闭包通知事件执行完成之后,会立即调用_publishe方法,向自己所有的订阅者发送结果
- 在收到一个订阅者要订阅自己的请求时,首先初始化一个Subscription(Conduit)对象,并将该Subscription对象添加到自己的Subscription数组中去。之后继续调用订阅者的receive(subscription:)方法表示已经建立订阅关系
至此,我们源码探究的第一阶段也就结束了,有的小伙伴可能在阅读源码的过程中就已经恍然大悟发现了其中的奥秘,如果还没有也不用担心,我在这里做一个对之上代码的小总结。
首先是关于只有一个发布者与订阅者组成的订阅系统中的内存持有情况,为了更好理解我花了一幅图,途中的箭头代表了持有关系,Publisher中持有Subscription的数组,以及Subscription中通过_parent属性持有上游发布者构成了Publisher与Subscription之间的两个箭头,Subscription中通过_downstream属性持有下游监听者构成了Subscription到Subscriber的那个箭头,其实这里还有一个箭头被忽略掉,上面的源码订阅者中存在一个state的属性,该属性为subscribed时,其内部的关联值会持有subscription,但是这个枚举值会根据订阅者的状态在内部自动改变,所以我们不用去考虑这层持有关系。

看到这里再结合一路close方法链执行的尽头(Subscription中的close方法)中所做的事情,我想大家应该都明白了,我们通过AnyCancellable也好,通过Cancellable也好,最后想要关闭的实际上是Publisher与Subscription之间的循环引用,如果不及时对这个循环引用进行破除,那么就会一直存在于内存中,随着软件的运行,这类循环引用所导致的无法释放的对象会越来越多,最后会撑爆内存。
那么为什么要有这个循环引用呢?答案是为了确保Publisher的存活,这个循环引用使Publisher得以继续在内存中存活而不被ARC所清理。那既然是这样为什么不采取在使用的时候直接将Publisher存储到当前类的属性中或者集合中的方案呢?毕竟这样的方法比现在的循环引用更容易被使用者理解,实现起来也更加简便一些。原因是,从语义的角度来看Publisher不应该被某个内部对其产生了订阅的类来管理,因为Publisher有时会在多个类之间传递使用,这样Publisher到底该由谁管理就变成了一个不是那么确定的事情,相反Subscription交由产生它的类管理是合理的,因为一个Subscription只会由一个类产生,通常也不需要传递给其他类使用,因为Subscription只是代表了一组订阅关系,拿在用户手里只相当于一个关闭订阅的token,没有其他的使用意义。除了语义角度之上的原因,更为重要的是在我们通过操作符组合形成的订阅链条中,存在着多个Publisher以及一个Subscription,如果通过保存Publisher来管理会变得非常复杂以及易出错,通过Subscription来管理整个链条就会很容易。
由于我们上面在分析Subscription的源码时使用了Future作为例子,所以我们在探索Subscription内部的同时也对Future的源码有了一定的了解,下面总结一下我们可以从Future源码中得到的东西。
- Future一旦被创建就会启动异步任务
- 异步任务执行完成之后,Future会将结果发送给所有已经订阅了自己的订阅者,并将结果保存起来
- 之后再有新的订阅者来,那就直接将保存的结果发送给订阅者
之前我们研究了只存在一个订阅者和一个发布者的简单订阅系统中的内存管理,接下来我们会继续深入探索由一个或多个操作符串联组成的订阅链条中的内存管理,最开始我们以比较常用的map操作符为例
1 | public func map<Result>( |
- map只是Publisher扩展的一个方法,该方法最终返回了一个Map对象
Map对象源码
1 | public struct Map<Upstream: Publisher, Output>: Publisher { |
- Map类中保存了上游的发布者upstream,以及要对上游发布的数据做的变换操作transform
- 同时Map类自己也是一个发布者,在接收到下游的订阅的时候,会将订阅者包装成Map.Inner在传递给上游让上游订阅
接下来来看Map中的内部类Inner的源码
1 | private struct Inner<Downstream: Subscriber>: Subscriber |
- Inner对象中保存了下游的订阅者以及要做的变换操作
- Inner实现了Subscriber协议,接收到上游发送过来的值之后就对其做一些变换之后继续转发给下游
看下面的一段演示代码
1 | func test () { |
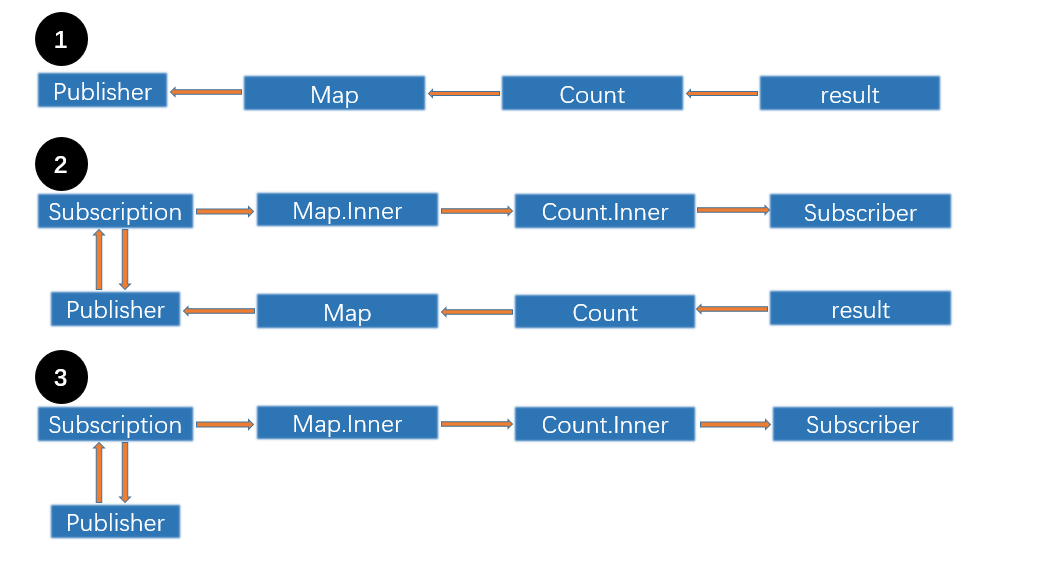
上面的代码中,使用map与count两个操作符构建了一个非常简单的订阅链条,注意代码中的逻辑不值得参考只用作演示。根据以上代码我花了一幅图,这幅图中的箭头表示对象间的持有关系,我将以上代码构建订阅链条的过程分为三个步骤。第一步,我们使用一个发布者和两个操作符构建了发布链条等待订阅者来订阅,同时最后返回的结果由result变量来保存,result在超出该方法的作用域之前不会被ARC回收,所以可以这个链条可以安全的存在于内存之中。第二步我们通过sink来订阅刚刚创建的那个发布链条,操作符对象(Map,Count)在接受到下游传递过来的订阅者的时候,会使用自己的内部类Inner对其进行包装,然后再将包装之后的新的订阅者对象传递给上层,最后会形成图中序号为2那样的持有关系。第三步超出test方法的作用域之后,由于存储发布链条的变量内存被释放,所以发布链条中的所有操作符对象也被释放,根部的发布者因为与Subscription的循环引用得以存活,整个订阅链条也得以存活。最后当我们调用subscription的close方法时,会断开subscription对publisher的引用,随后整个订阅链条都会被释放。
如果Combine的某个发布者链条会在多个类中流转或者将有多个订阅者订阅时,我们被要求或者建议在发布者链的末尾加上share或multicast操作符。在使用Combine封装网络操作中,我们被告知如果不使用share或者multicast操作符,极易会出现我们不期望的重复网络请求的情况,从而浪费系统资源。这到底是为什么?其实是因为大多数的发布者以及操作符都是使用struct来封装的,在各个类之间流转或者多个订阅者对其进行订阅的时候会发生值得复制,复制的程度取决于你的发布者链的构成,如果你的整条发布者链条都是由值类型的发布者或者操作符组成的,那么每有一个新的订阅者订阅都会产生一个新的链条,整个链条的状态将会被重置从而导致资源的重新请求。
我们可以使用multicast或者share操作符来抹除这种发布者链条的复制行为,到底是怎么实现的呢?让我们从Multicast操作符类的源码开始
以下省略了部分锁相关代码
1 | public final class Multicast<Upstream: Publisher, SubjectType: Subject>: ConnectablePublisher |
- Multicast操作符需要外部提供一个subject,这个subject可以是懒加载的。在Multicast类中,Combine使用两个属性来实现懒加载的属性而不是直接使用lazy,是因为lazy不是线程安全的, Multicast通过自己来控制锁的行为来实现线程安全的懒加载
- 在接到下游的订阅请求时,会将下游的请阅请求通过Inner包装之后转发给自己属性中拥有的那个subject
- connect方法是ConnectablePublisher在Publisher协议的基础之上新增的约束方法,在这里的connect方法中,将自己属性中的subject与上游的发布者建立连接:即将自己属性中的subject作为订阅者订阅上游发布者
至于Multicast中的Inner,只是简单的实现了上游到下游的数据传送,跟我们之前分析Map的Inner是一样的只是少了map特有的数据变换的逻辑,这里就不再列出来分析了,如果读者想看,可以点击这里
看过了上面Multicast的源码之后,我们可以使用一张图来总结Multicast的行为。第一步,我们对一条以Multicast结尾的发布者链条进行订阅时,并不能形成一条从头至尾的订阅链,下游的订阅者会订阅Multicast内部的一个Subject,然后就止步于此。第二步我们对返回的Multicast对象(ConnectablePublisher)调用connect方法,Multicast中的subject会与上游发布者链条建立连接,然后才能形成一条完整的订阅链。
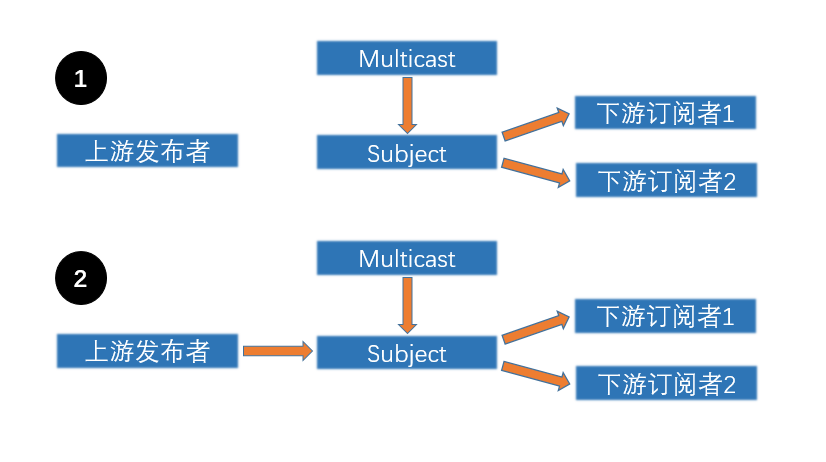
Multicast通过其内部的一个subject将上游发送下来的数据转发给下游,正常情况下与去掉Multicast直接订阅没有什区别,但因为内部的subject被声明为引用类型(Class),可以有效的对下游屏蔽其上游存在值类型发布者的细节,同时Multicast自身的类型也是一个引用类型(Class),所以使用者拿到multicast操作符返回的对象之后可以肆无忌惮的在各个类之间流转,而不用担心因为值类型赋值发生复制而造成的各种各样的问题。同时我们还可以通过传入不同类型的Subject而控制对上游数据的缓存行为等。
理解了Multicast,其实就是已经理解了share。为什么这么说呢,看一看share的源码就知道了
1 | public final class Share<Upstream: Publisher>: Publisher{ |
- share默认使用的Subject时PassthroughSubject
- 内部使用了multicast,并且初始化时传入一个符合类型的subject,并且调用了autoconnect
- 下游对share操作符返回的对象进行订阅其实就等于对刚刚生成的multicast对象进行订阅
通过源码我们可以看到,share操作符其实就是一个对multicast操作符的封装,在multicast的基础之上提供了默认的用于转发的subject以及附加了autoconnect。
到了这里我们已经完成了关于Combine中内存管理相关源码的所有探究,有没有觉得对于Combine日常使用的代码有了更加清晰深刻的认识了呢?如果还是不太懂得话可以按照文章中得这个步骤再去源码中看一下哦。
这篇文章除了想要向大家展示Combine中的内存管理方式之外,更多的想要传达给大家的是日常开发时遇到难题或者为了技术提升而去阅读源码的一种方式。看完了这篇文章再从头到尾捋一下文章中源码探究的流程,就可以发现我们到底是怎么从代码的最外层(API)一步一步深入到底层,直到找到想要的东西,又是怎么举一反三,将代码中的某个组件的行为推广到整个层级的行为,从而大大降低了我们为了去了解某个东西而耗费的精力与时间。这样的源码阅读方法或者说思想对想要自己探究源码的人十分重要。最后一句:源码,永远滴神。好了,那我现在走了