Kubernetes出现的背景
在早些年的时候,我们几乎所有的应用都采用单体的模式,他们通常以一个或多个进程的形式运行在一台或多台物理主机之上。在这种模式下,应用的发布周期长,迭代也不会特别的频繁。开发团队会共同开发这一个大的单体应用,并且在开发完成之后将程序打包交给运维人员,之后再由运维人员来负责程序的部署上线以及监控事宜。
但在今天,大型的单体应用在逐渐的被分解成一个个小的组件,我们称之为微服务,这些组件彼此之间松耦合,所以可以由开发人员独立开发并且独立部署。这样的架构模式很大程度上增强了程序的可维护性(因为不同组件之间被隔离开,单个程序中的逻辑更加的清晰)与迭代速度。但是各种伴随着微服务架构而出现的难题也不断的出现。在一个大型应用体系之中,会拥有很多个组件,而且组件之间也会有很复杂的依赖关系,组件的迭代速度也要比之前快很多,这就使部署,监控以及管理组件变得越来越困难。手动实现所有这些事情变成了几乎不可能,这就是Kubernetes出现的原因,K8s帮助我们自动地调度、配置、监控这些组件,并且在组件出现错误时及时地对错误进行处理。
Kubernetes整体架构
在如今许多中大型规模的公司中,使用kubernetes管理上百台服务器以及上千个服务组件是一件司空见惯的事情,那Kubernetes是如何让在过去传统的运维时代看起来几乎不可能的事情变得“司空见惯”的呢?下面我们先来讨论下Kubernetes的整体架构,让我们对这个强大的应用有个初步的了解
Kubernetes整个系统由一个主节点与若干个工作节点组成,为了能够更好地理解各个节点之间的关系,我花了一幅草图,图画的不是很好,将就着看一下。下图中主节点主要的作用是管理整个系统的配置,对外提供配置系统的接口,同时负责协调各个工作节点之间的工作。工作节点的主要作用就是运行用户实际部署的组件或者应用
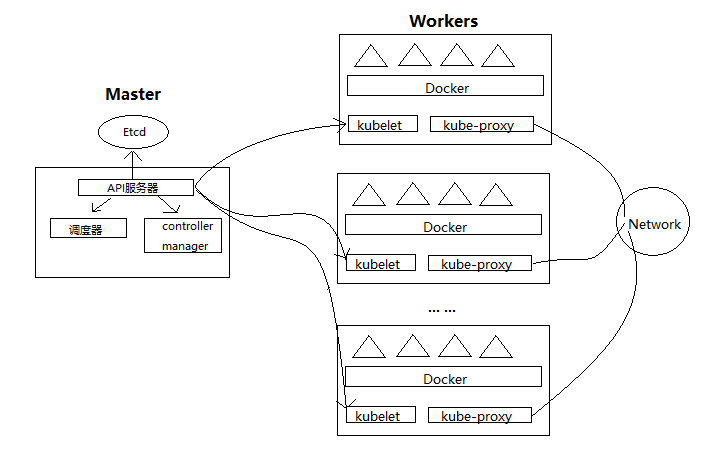
主节点:
API服务器:任何受控组件都要与API服务器相连,API服务器可以从这些受控组件处获取当前系统的一个状态,受控组件也可以从API服务器处获取自己要做的事情。
调度器:调度器负责调度你的应用,调度器会根据当前系统的状态来得出现在是否需要部署新的应用,以及要交给哪个工作节点来部署这个应用
controller manager:主要负责集群之间的关系,如监控跟踪工作节点以及处理工作节点出现错误等
Etcd:是Kubernetes所依赖的外部数据存储组件,用来持久化集群配置
*工作节点**:
kubelet:是工作节点上的受控组件,它会告知API服务器当前节点的状态,并从API服务器那里获取自己需要做的事情
Docker:运行在工作节点上的容器系统,这里只是以Docker举例,也可以是其他的容器系统(rkt等等)
kube-proxy:负责各个节点之间的网络通信以及流量负载均衡,各个节点之间通过proxy构建了一个属于Kubernetes系统的网络,所有运行在此系统中的组件或者应用都可以看作是在同一个网络当中
Kubernetes的整体架构大概介绍到这里,关于以上的介绍这里还有几个格外需要注意的点
- 主节点(Master)只负责跟踪并控制各个工作节点的状态,但并不运行应用
- 主节点(Master)和工作节点(Worker)可以部署在同一台物理服务器上
- 一个Kubernetes系统只能由一个主节点(Master)和若干个工作节点(Worker)构成
Kubernetes中的对象
Kubernetes的对象是我们进行应用调度的重要依据,Kubernetes的对象其实就是持久化的实体,这些实体描述了集群中所运行的应用一节这些应用的状态与占用的资源。所以在我们想要继续深入了解Kubernetes这个庞大的系统之前,我们要先关注一下Kubernetes中的对象。
Kubernetes中的对象在代码层面上表现为一个接口,而不是一个结构体,对象结构中定义了一系列的Getter/Setter方法
1 | type Object interface { |
而对使用者来说,Kubernetes中的对象主要有以下几个部分组成
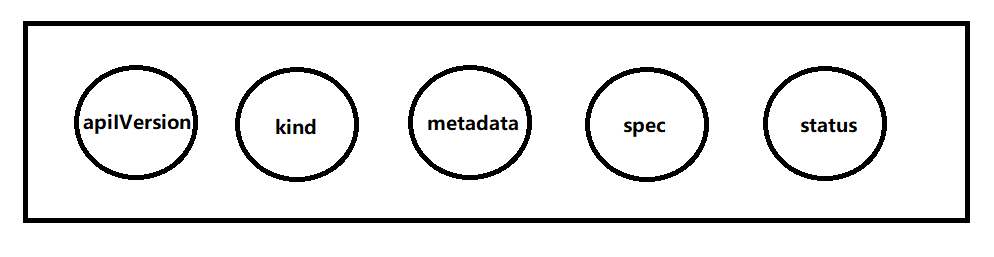
- apiVersion:指定API组,决定了当前的对象应该由哪个组件来处理
- kind:描述了对象的类型,kubernetes的对象有好多种,这个kind决定了对象的类型以及构建的方式
- metadata:可以为我们提供一些对象的扩展信息
- **spec(规格)**:描述了我们所期望的一个对象的状态,可以看作是我们所构建的这个对象的构成。
- status:是Kubernetes集群对外暴露的可以描述对象运行状态的接口
spec与status与kind具有很强的关联性,不同类型的对象的spec与status是不同的,所以我们这里讨论kubernetes中的对象的时候,先只讨论不同类型通用的metadata,其他的会在介绍特定类型对象的时候进行说明
Metadata(元数据)
Metadata在对象中给我们提供了一些很有用的扩展信息,我们可以基于元数据来唯一识别一个对象,以及将多个对象组织与分类
1 | apiVersion: ... |
标签与选择器
每一个Kubernetes对象都可以被打上标签,我们可以使用标签选择器来快速匹配到我们想要的对象,当你的系统中的对象越来越多的时候,标签便是一个不可或缺的功能,没有了标签你将难以管理种类繁多数量巨大的对象集合。例如下面的命令可以直接帮助我们获取生产环境中的app为myapp的所有pods。
1 | kubectl get pods -l environment=production,app=myapp |
除了使用以上命令行的方式获取对象之外,我们也可以在构建对象时来指定标签选择器来达到相同的效果。之后我们会了解到,一部分对象是需要靠自己内部定义的标签选择器来工作的
1 | selector: |
namespace(命名空间)
在上面的标签中我们可以看到,在真是的项目运行环境中,我们经常会有生产环境与测试环境两组不同的运行中的应用,而我们知道,一般生产环境与测试环境的应用是要隔离开来的,以免应用的一些系统级的行为对其他应用造成影响而这就是namespace(命名空间)存在的理由,不同的命名空间可以对资源进行隔离,例如在一个命名空间中的对象无法直接使用服务名称来直接访问另一个命名空间中的服务。
总结元数据的使用
通过以上信息,我们可以看到kubernetes的元数据为我们提供了可以快速分类和管理集群中大量对象的方法,为我们的应用实现提供了更大的可能。但是我们需要意识到的是,kubernetes只是给我们提供了这样的一种接口,其中的标签和命名空间仍然是由我们自己来编辑和选择的,如果滥用标签和命名空间,不仅不会是管理不同的对象变得便捷,有时还会对系统的正常功能造成影响。所以我们最好在使用标签与命名空间之前,定义一套属于这个系统的标签使用规范。这些规范应包括:
- 可以使用的标签的集合,在使用标签时,应禁止使用集合之外的标签
- 集合中的每个标签的可选值以及语义
- 集合中有哪些标签是每个对象必须使用的
- 集合中有哪些标签是特定类型对象必须使用的
- 集合中有哪些标签是特定类型对象不能使用的
- 命名空间集合,系统中不应该出现集合之外的命名空间
- 命名空间集合中每个空间的语义,以及哪些对象应该放入该空间